本文又名十行代码帮你撩妹。
需求
今天沙沙在群里向我们紧急求助,领导让她整理【携程江湾五角场地区的260家酒店的名称,价格,地址,网址,评分信息制成excel】。
PM(也是前php开发者)咕咕推荐了【八爪鱼】这个工具,不懂技术的小白也能抓取数据。
作为一个程序员,很惭愧的说自己其实没接触过爬虫,之前说的要学python也没学几天就放弃了,现学肯定来不及了,作为一个不懂python的前端,如何帮上沙沙的忙呢?
思考
其实也就是返回的json处理一下嘛,我们先来看看页面的逻辑。
先访问列出这260家酒店的url:http://hotels.ctrip.com/hotel/shanghai2/zone368#ctm_ref=hod_hp_sb_lst。
在chrome devtool的network中选择xhr,凭借我们多年的工作经验,来判断下到底是哪个接口返回了hotelsList的信息。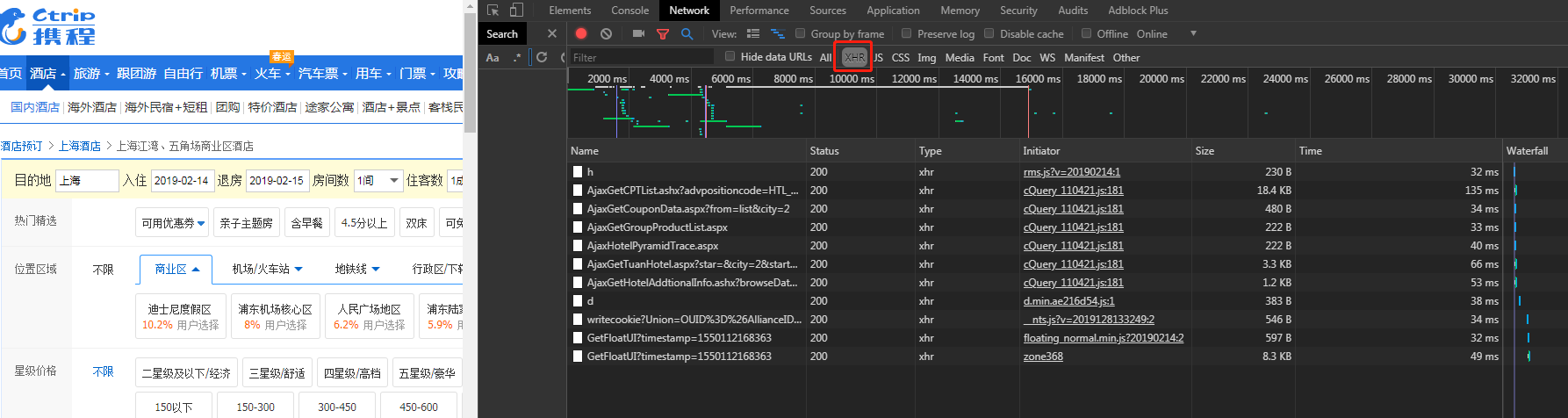
先锁定了/AjaxGetGroupProductList.aspx这个接口,本以为直接copy下json,简单处理下就完工了,顶多有个分页
需要多次请求。但是what?这个接口居然没有response body!
回想起之前看到很多反爬故事的文章都出自携程和去哪儿,怎么可能这么容易就被爬到数据呢?
分析接口这条路可能还需要点成本,冷静下思考,其实小伙伴的要求并不高,数据量也并不大,说不定只通过前端知识就可以获取到我们想要的结果。
试了试八爪鱼,看起来也是设定好需要的div,获取div。马上有了思路,既然接口hook走不通,不如前端老本行,所见即所得,通过jquery直接获取页面上的元素,界面是不可能骗人的,那我们开始写代码。
Coding
1 | let num = $('.hotel_item').length; |
但是酒店数据是分页显示的,只好手动一页一页的点击运行来获取。
Tips:
1.这里用到了chrome devtool的snippet,可以保存在chrome里,直接右键run一下就可以运行。比直接粘在console里要灵活。
2.携程本身的页面有jQuery,所以我们可以直接使用jQuery。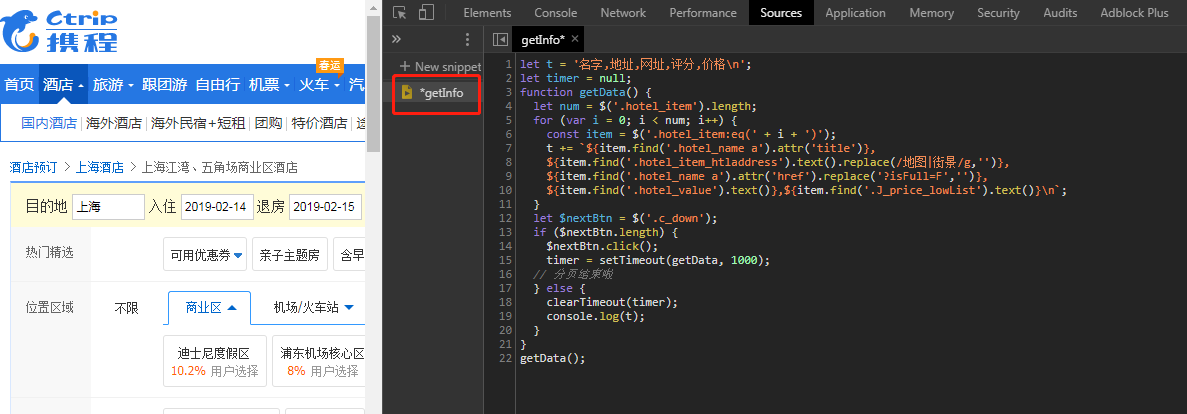
优化
手动翻页也太low了吧,后来惊喜的发现居然是单页应用,点击下一页并没有刷新页面,我们可以用代码来帮我们直接点击。
1 | (function() { |
这样就可以自动翻页,完成时会把我们想要的数据直接console出来。
然后再找个转csv的工具就可以啦,时间紧张,先发给沙沙吧。
讨论
虽然这篇的技术知识很简单,可能算不上爬虫,但我们可以回过头来分析下这个例子中携程是如何做反爬的。
首页的数据太多太杂,点了第二页,查看了下
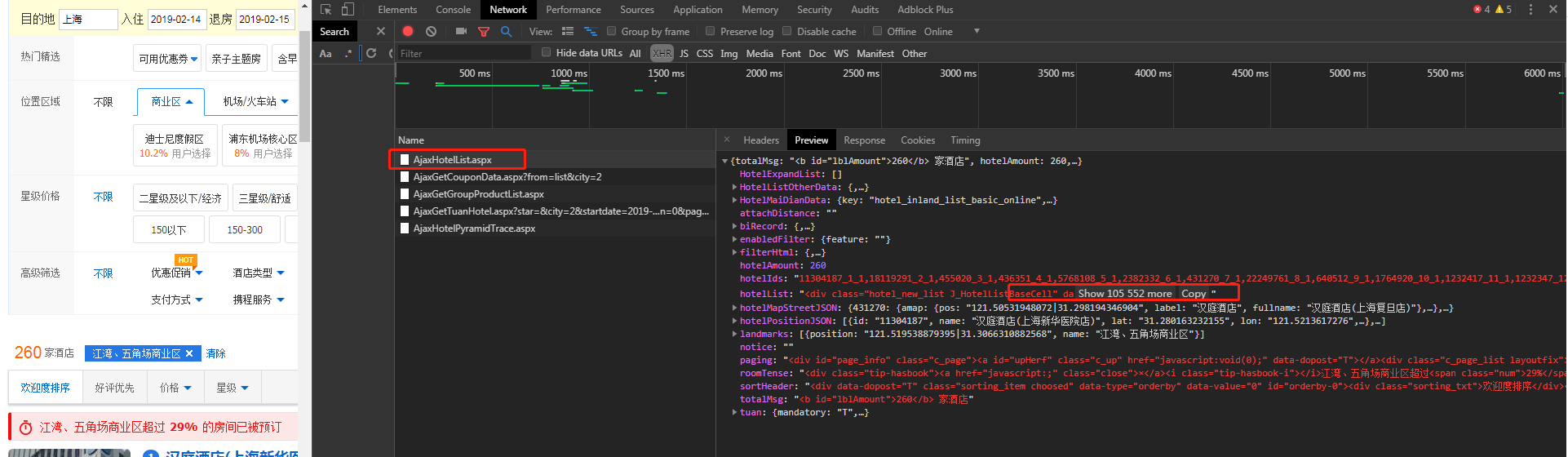
/AjaxHotelList.aspx才是真正的接口,我们需要的数据实际也不是json,而直接是html信息,这样坏人需要写很多的正则来获取,需要懂一些前端知识,而且作恶成本很高。
这个接口足足有182kb的大小,性能优化和反爬需要有个平衡。
所以这种数据量比较小的,没有时间要求的,还是从前端的角度来抓取数据会更靠谱一些。
思考下首页为啥没有这个请求数据的接口呢?
可能是考虑到首页SEO及渲染速度选择了服务端直出,所以有经验了我们就是应该直奔第二页,明白套路就能少走弯路。
总结
1.接口返回的并不是规则的json数据,并不好解析,我们可以使用前端的jquery直接获取需要dom属性。
2.我们使用了chrome的Snippet功能,直接在页面中运行代码即可,还可以保存常用的util代码,比直接写在console中会优雅一些。
3.观察到是单页应用,可以自己写代码来点击切换到下一页。
4.json如何导出成excel呢?其实我们常用的一般都是csv文件,只要通过tab来分隔就可以了。
5.读取本地json文件$.getJSON
思考
虽然完成了,得到了技术小白沙沙的赞美,但是心里还是很虚。
主要问题有:
1.手动的可以全部自动化吗?
可以直接写入csv文件而不是copy console里的内容吗?
虽然传统的js是运行在浏览器中的,为了安全起见是不可以读写本地文件的,但是发现HTML5有新的API可以导出文件。但是这样还是勉强了些。
2.沙沙弱弱地说如果可以获取酒店的开业时间和房间数就好了。
嗷的,那还得点进去每个酒店的detail去查看,十行代码搞不定啦。
我知道可以使用webdriver,phantomJS等来模拟点击,具体的还有待研究。
不用担心,下篇文章我们会鸟枪换炮!
后记
只需要很少的代码量就可以达到我们的需求,js真的很强大呢!前端很好玩,能把前端用在生活中那就更美妙了,可以抢火车票啥的。
心虚的说了句要赶紧学python啦。另一只小白问要怎么才能学会编程,学了几天python没有动力就不想学了。
我觉得用一劳永逸的懒人思维思考问题,慢慢自己给自己提需求,这样就能发现科技的力量和智趣。
